A Joint Disclosure by Udanax.com
and Project Xanadu
as of August 23, 1999
to accompany our
presentation at the O'Reilly
Open Source Conference
Xanadu®
Technologies-- An Introduction
A Joint Disclosure by Udanax.com
and Project Xanadu
as of August 23, 1999
to accompany our
presentation at the O'Reilly
Open Source Conference
Xanadu®
Technologies-- An Introduction
WHAT THIS IS
Udanax.com (formerly XOC, Inc.) have agreed that the softwware until now referred to as "Xanadu" (particularly Xanadu 88.1 and Xanadu 92.1) is now to be released as Open Source under the X license. All data structures previously held as trade secret by XOC, Inc. are deemed to be no longer secret and all associates and past members of Project Xanadu and XOC, Inc. are released from their non-disclosure agreements with respect to these strucutures.BASIC CONCEPTThis page, (and the other accompanying pages at xanadu.com and udanax.com), are the first publication of what have been called the "Xanadu Secrets", in particular, Enfiladics and the Ent.
The shortcomings in this presentation, which are considerable, are entirely due to a lack of time and resources to document what we have done. However, we will endeavor make available all the technical material we can find, either on the Web or through paper publication. Some of these materials are scattered and have been brought back together with considerable effort.
All the structures and algorithms discussed here were disclosed at the Open Source Conference (to the extent that time allowed), and are being made available on the Udanax Website thereafter, in addition to this page at xanadu.com.
The two principal bodies of Xanadu code from 1998-92, until now called Xanadu 88.1 and Xanadu 92.1 respectively, will be packaged for distribution at the Udanax site under the names "Undanax Green" and "Udanax Gold". We desire that development of both shall go forward according to the Open Source model, with contributions from programmers of good will around the world.
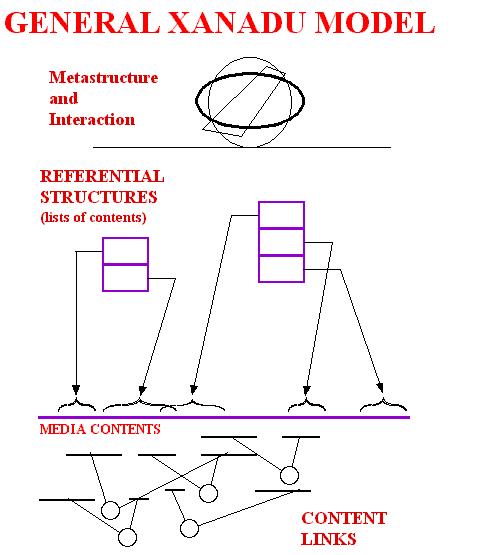
The principal insight was in place by the end of December 1960. It was this: if text and other media are maintained as referential structures, the resulting structure will have numerous powerful advantages over merely moving the contents around.VISUALIZATIONThe links (unlike the later links of HyperCard and HTML) are between sections of content.
The advantages of this structure include:
LINKS CAN ADHERE TO CONTENT: if the content moved, the links are still connected.All these ideas are discussed elsewhere, esp. in Literary Machines, The Future of Information and at Ted Nelson's web pages.
ANY NUMBER OF OVERLAPPING LINKS MAY BE CONNECTED TO THE SAME MATERIAL.
CONTENT CAN BE MOVED WITHOUT BREAKING LINKS
Therefore we may have a NEW COPYRIGHT MECHANISM: DELIVERY ON LINE, WITH SALE OF PORTIONS BY INDIVIDUAL RIGHTSHOLDERS. This could make possible a new copyright mechanism, with unrestricted re-use without breaking either links or copyright.
(Moreover, TRANSCLUSIONS CAN BE SHOWN BY ADDRESS COMPARISON.)
While this idea has always been simple to state, the details must be reconciled carefully, and have resulted in a number of different models. (There are always difficulties in resolving details to a clean design.) A very simplified version was published in 1965 (Nelson, "A File Structure for the Complex, the Changing, and the Indeterminate". Proceedings of ACM Twentieth National Conference, 1965.)
Nelson first presented this idea to a technical group at Brown University in 1968. (That version was called SNP, for "Sexus-Nexus-Plexus", divided into the illustrated levels: content, referential document lists, and links.) The others called the design "raving", so it was dumbed down to one-way links. When asked how the user would get around, Nelson suggested a stack of locations visited. The resulting implementation was the Brown University Hypertext Editing System (CITATION TO CHECK: Carmody et al., "A Hypertext Editing System for the 360", in Faiman and Nievergelt (ed.), Pertinent Concepts in Computer Graphics, 1968).
This dumbdown cast a long shadow. While the exact pathways are difficult to delineate, it appears to have established the design of the World Wide Web and the browser as we know it.
In any computer project, the problem is always finding constructs which are sufficient but clean. We published these illustrations in 1972 (simulated in the pictures with cardboard and clear plastic above a Selectric keyboard) to show an extremely simple way of showing two-way links and transclusions.EARLY TECHNICALITIESThe idea was of course to see the connections in their two-way reality. The connection-lines should go between the contents of the windows, so that either window may scroll or be moved independently.
Unfortunately, due to the politics of standardization and other social processes of the computer world, the windowing standard became that later designed at Xerox PARC, which mimicked paper instead, and could not show connections. Furthermore, 1-way links became the prevailing concept; such links could be followed only from origin to target, and never displayed side-by-side.
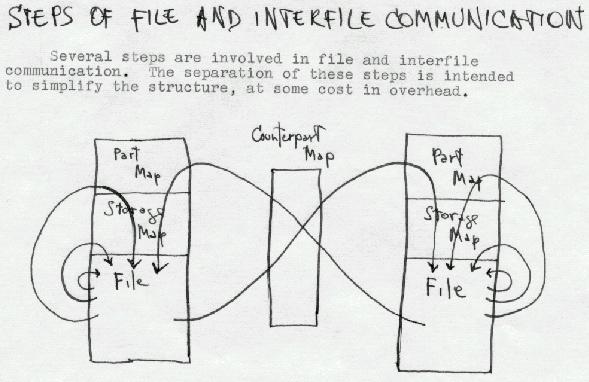
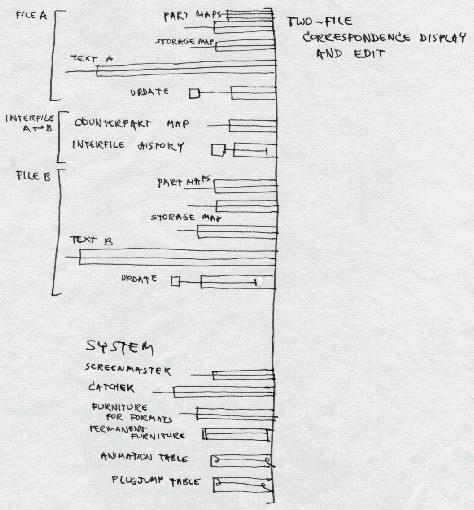
The first eleven years of Project Xanadu was Nelson either by himself or with an occasional single collaborator.A BRIEF HISTORY OF ENFILADE WORK AT PROJECT XANADUTo implement the sort of interconnection shown in the photographs above, various technicalities were devised. This illustration is from a 1971 document, showing the steps for sideways intercomparison (as shown above) in a relatively conventional file representation.
Data structures to suport this were to use parallel files linked in parallel ways corresponding to the parallel visualization:
However, it was becoming obvious that more generalized structures would be necessary, to support links and transclusion among documents and versions taken more than two at a time.
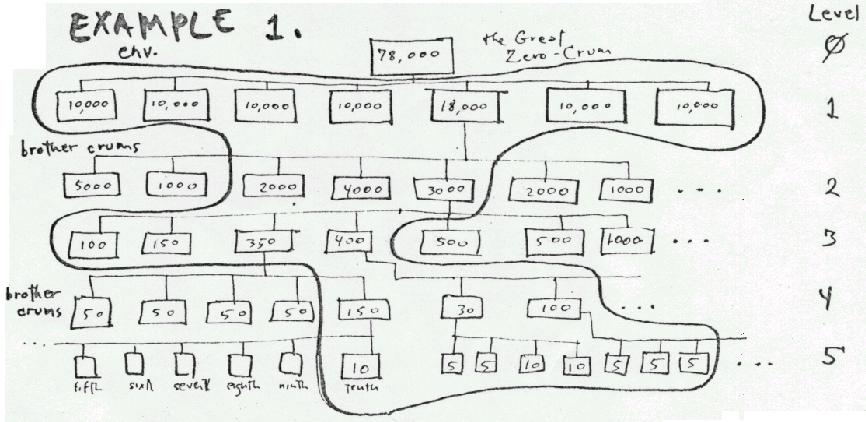
The first enfilade (the "model T") was invented/discovered by Nelson in 1971-2, with the assistance of Jonathan V.E. Ridgway and the late Cal Daniels. (To the best of our knowledge, it was about eight years before others published similar methods.)*ENFILADES [the *name-with-asterisk denotes content which was previously trade secret information of XOC, Inc.]
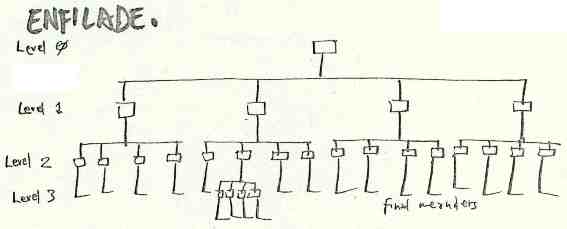
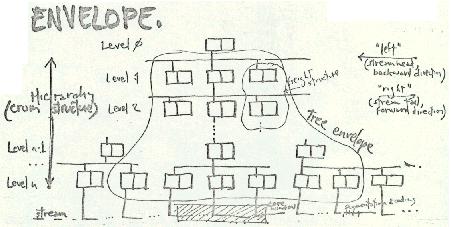
"Enfilades" are a class of data structures (and of course their corresponding algorithms). While a number of enfilade discoveries have since been published by others, the underlying generalities found by the Xanadu group have not, to our knowledge.*THE MODEL T ENFILADEAs widely suspected, enfilades are principally tree structures, but with a number of additional key features of interest.
The Model T was originally designed as part of the JOT project, a subsystem of Xanadu design for editing large bodies of text on cassette tape. (Only accidents prevented the completion and release of JOT in 1973 as the first personal word processor.)The text itself would not move, but pointers to it would be rearranged.
In order to function with large bodies of text, a tree structure for pointer-based editing was devised. An intrinsic design intention was to allow the tree to grow to any size by systematically maintaining a subrepresentation of the tree in core-- in other words, system-supported caching particular to this method.The central feature of technical interest was that each pointer contained a count of the numbers of characters below (a field we called the WID, since it showed the width of contents referenced underneath). This is indicated in the following picture as the second square of each pointer.
The lowest-level pointer (level n in the above illustration) pointed directly to a text segment. Its WID was the length of that segment. Above level n, the WID field summed the WID fields below.This sum of WIDs propagated up the tree to the root pointer, whose WID therefore contained the text length of the entire document. This arrangement made it possible to go directly to any location in the document, by evaluation of the WIDs on the way down to the final content.
EXAMPLE OF USE
Today's word processors typically offer only rudimentary rearrange, by deleting text into a buffer (the misleadingly so-called "clipboard", rather than the richer forms of rearrangement in constant use by prose authors). We designed the 1972 system for rearrangement of two sections to be exchanged, either consecutively or around an unmoving section. (These were respectively called the Switcheroo, with three cuts defining two sections, and the Switcheroonie, with four cuts defining three sections.) An author was to delineate the cut-points with exclamation points (a convention later adopted by Word Perfect). These cuts would then be transferred to the structure of pointers and be applied to the contents below.
The following example shows how three cuts would determine a rearrangement.
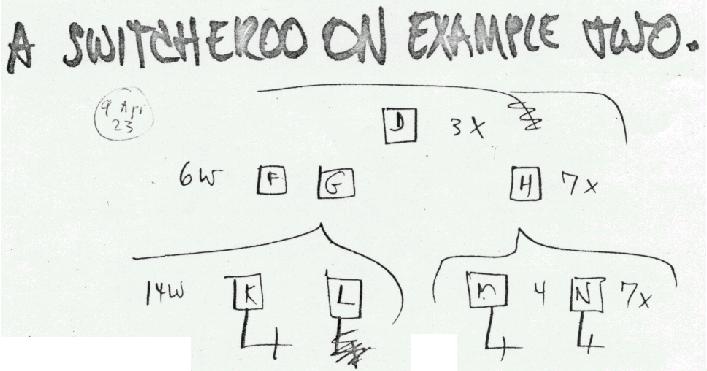
Internals of rearrangement, Model T enfilade, 1972. Letters here identify reference pointers ("crums") being kept in core.
THE CRUM TABLE
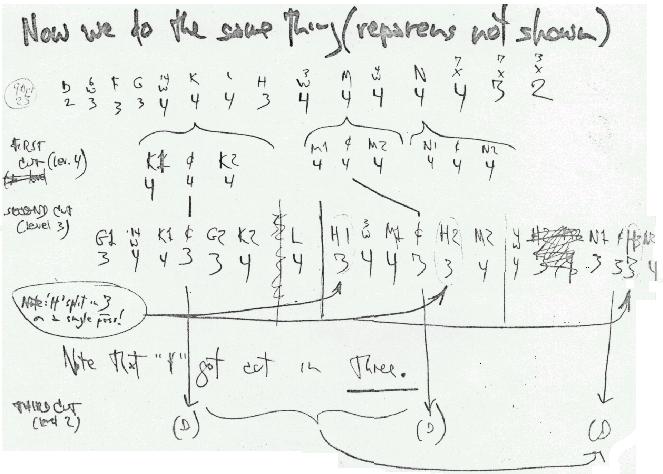
*THE BARUS CONJECTURECrum Table enacting rearrangement in the previous illustration. The crum table shows how the rearrangement is enacted within a buffer containing and identifying the crums. A numeral is associated with each crum, showing its level in the tree structure of the enfilade, thus modelling a subrepresentation of the whole structure. The lowest-level crums (level 4) point to string data. WIDs are not shown.
In this map, the three-cut rearrangement of the previous illustration is mapped into its constituent operations on the crum pointers. The "¢" symbol indicates a cut to be made in the crum, specfically to crums K, H, M and N, which we see propagated up to the highest necessary level. A rearrangement of the crums (and sending the crum table to mass storage) completes the rearrangement of the text below.
The first two rows of the illustration identify the crums of a subrepresentation of the enfilade, starting with D, a crum at level 2. Passing rightward, six crums are omitted from the map; then F, a level 3 crum (not involved) and G, a level 3 crum, where the work begins. Below G are 14 level-4 crums (omitted), then K, a level-4 crum involved in the operation, and its succesor L, not involved. We see H, a third-level crum involved in the rearrangement, above M; four other crums are not shown, N (involved in the operation), and then other crum-counts of crums which are omitted.
In the third level of the diagram, showing only a part of the table, we see the cuts propagate to the bottom level as the rearrangement is consummated. Sections of crums are exchanged, after which the "¢" symbols may be removed from the crum table.
To enact the operation, K, M and N are cut. In the method illustrated here, the "¢" sign is used as an actual marker in the crum table. Crum K is replaced by crum K1, the "¢" sign and crum K2. Crum M is replaced by Crum M1, the "¢" sign and crum M2; crum N is replaced crum N1, the "¢" sign and crum N2.
In the last level of the diagram,
Depending on the depth of the tree and whether the upper crums contain all the affected contents, the cuts may have to propagate to additional levels, which can be easily done by iterating the same method.
William Barus, then a philosophy graduate student at the University of Chicago, generalized this basic enfilade in surprising directions. He conjectured that version management could be handled by separately maintaining two sets of pointers to the content-- the original input sequence, and a current version. This approach led directly to the other conceptual breakthroughs.*GENERAL ENFILADE THEORYBased on Barus' discoveries, the Xanadu group gathered for the "Swarthmore summer" of 1978. This led to
1) the discovery and elucidation of General Enfilade Theory; 2) the design of the Xanadu 88.1 system (Udanax Green); 3) the discovery of the Ent; and 4) Xanadu 92.1 (now Xanadu Green)
(The reader should understand that this brief introduction is not the whole of the theory, and is referred to the originators or to Roger Gregory.)XANADU 88.1 (now "Udanax Green")General Enfilade Theory was discovered and elucidated within the group during this period (though still not published) by Mark Miller and Stuart Greene (now Stuart Grace). They discovered that enfilades had two basic properties which could be independently tailored to create powerful data structures as needed.
The two properties were called WIDativity (upwardly-propagating properties, such as the WID field of the Model T enfilade) and DSPativity, which was also present (though unsuspected) in the Model T enfilade. DSP, standing for "displacement", applies to properties which propagate cumulatively downward, being imposed from above.
Example: in computer graphics, a WIDative property (upwardly cumulative) is the bounding box, which grows as the tree included becomes larger. A DSPative property is matrix rotation, such as that of a finger of a hand on an arm, where the movement of a single bone of a single digit is a matrix product of all the motions farther up the tree.
What was the DSPative property in the Model T? It was the sequencing of the pointers, which sequenced the text below in a tree of downward imposition.
Both WIDative and DSPative properties must be associative, i.e. for such a property p
A p (B p C) = (A p B) p C because there is no telling how the next version will be edited. However, WIDative properties must be associative horizontally (like the sum of the WIDs in the Model T enfilade) and DSPative properties must be associative vertically (like the positions of the crums in the Model T enfilade).
General Enfilade Theory permits the creation of custom enfilades by the suitable selection and design of WIDative and DSPative properties.
The Xanadu 88.1 system was designed by Roger Gregory and Mark Miller in 1981, and essentially completed in 1988. This system, described in our defining book Literary Machines, searches a vast address space such as the Internet, creating a distributed representation of the system on many servers. Each server manages its own dynamically explored subrepresentation of the whole. Each node may subcache portions of the docuverse as required. The whole space may be searched with unusual efficiency for overlapping content links and transclusions.*THE ENTConsider the linear address of the docuverse, or a subset, as a line. (See illustrations in Literary Machines). This address space is measured in tumblers, which are multipart numbers of the form 0.zzz.yyy.xxx ..., where the fields "zzz", etc., are any integer. The zero is convenient for the calculation. The first field zzz represent a node, the second field yyy represents an account (perhaps author or company), the fourth field xxx represents a particular work, the fourth field wwww represents an address within the work, and the fifth field vvv represents the element type. What is particularly interesting is that stretches of the docuverse are represented by a starting tumbler and a difference tumbler, manipuated with unusual numerical address operations based on transfinite arithmetic. (This is presented in Literary Machines.
*PREVIOUSLY SECRET INTERNALS OF 88.1/U.Green
*The Istream. Consider the docuverse order of content pieces (sometimes the local order of arrival and storage) as the invariant stream, Istream or I. (It is not going anywhere, and will be rearranged in place.)
*The Vstream. A current permutation of a document is represented by another ordering of the same contents. This is called the variant stream, Vstream, or V. This rearrangement V is represented as a permutation matrix.
It was explained in Literary Machines that tumbler arithmetic is used for calculating spans of addresses. Actually tumbler arithmetic is used for address matrix operations throughout the system.
*ENFILADES OF U.GREEN. There are three interacting enfilade structures: the Granfilade, the Poomfilade, and the Spanfilade.
*The Granfilade (Grand Enfilade) manages the content of the whole address space, similar to the function of the Model T enfilade. As new content is added throughtout the docuverse, its presence percolates upward as counts in the whole system. (How this is distributed is another matter.)
*The POOMfilade (Permutation Of Order Matrix Enfilade) is local to a document. It provides the I-to-V and V-to-I transform-- that is, given any location of contents in the address space (an I-address) it finds the corresponding current address of that element (V-address), and vice versa.
*The Spanfilade (Spanning Enfilade) is where the real work of the system occurs. It provides V-to-V transforms, making it possible to go from a Vstream address in one document to the Vstream address of the same content in another document. This is the address comparison for both links and transclusion spoken of earlier. The spanfilade is also intended to provide the sieving function that filters out the irrelevant connections.
The Udanax Green code is in C.
Udanax Green ran on a small scale, but development was stopped in favor of an improved design, the less-finished Udanax Gold, based on Drexler's Ent.
The Ent was invented/discovered/designed by K. Eric Drexler (discoverer/inventor of nanotechnology and head of the Foresight Institute). The Ent, named after the walking trees with great memory in J.R.R. Tolkien's Lord of the Rings, is a data structure and algorithm plex which manages complex versioning of arbitrary objects with low overhead and great parsimony, representing each version simply by a handle into complex of data.XANADU 92.1
Xanadu 92.1 (now Udanax Gold) was architected by Mark Miller (who later acknowledged as his co-architects Dean Tribble and Ravi Pandya.).AVAILABILITY*PREVIOUSLY SECRET INTERNALS OF 92.1/U.GOLD
This consisted of the Ent and various object-oriented wrappers for it, seeking the most robust, efficient and generalized version. Xanadu 92.1 was still unfinished when Autodesk dropped the Xanadu project in 1992.
Xanadu 92.1 system was based on wrapping the Ent, mapping it to a highly-generalized multidimensional coordinate space for arbitrary data, and encapsulating requests and deliveries for efficiency.
Design of 92.1 began in 1988. At that time, object-oriented programming tools for large projects were in poor shape. The group chose to maintain identical parallel code in a carefully-chosen mutual subset of Parc Place Smalltalk and C++, in order to obtain certain benefits from each.
The U.Gold code has satisfied certain tests but is not considered to be usable as yet. However, the kernel Ent routines, wrapped by the rest of the system, have worked well since about 1990. It may be an interesting project for someone to endeavor to extract the Ent code from U.Gold (the name for the distributable version of Xanadu 92.1), in the same manner that the "curses" library was extracted from Bill Joy's vi text editor.
The code will be available from the udanax.com website, with a release date of 23 August 1999.LICENSES AND TRADEMARKS
Release will be under the Berkeley II open source license, requiring no acknowledgment of use.To avoid confusion with present work at Project Xanadu, the names "Udanax Green" and "Udanax Gold" will be given to these packages and their ongoing versions. However, this software was called "Xanadu Code" in the past, and of course any reference to it in the past tense may correctly refer to it under the trademark "Xanadu". It is just not being called Xanadu from now on, as it spins off into new adventures.