ZZ Cell Programming
It is time to return real programming to users and even beginning users, to whom it has been denied since 1984.
We want to make it easy for users to program, creating their own scripts and loops of function-- especially position and animation of contents in space, response to users, numerical functions.
But of course richer possibilities could include using the space and structure for complex simulations, Alife programs, etc.
THE PECULIAR ADVANTAGE OF ZIGZAG FOR PROGRAMMING CONSTRUCTS
The problem of programming is fundamentally the problem of human visualization and understanding of what we tell want our machines to do, and relating such plans to what we *want* them to do. The popular and conventional programming systems represent particular compromises and styles of trying to manage this complexity.
But ZigZag space and structure suggest other ways of doing it, as a combination of visual, spatial and abstract understanding.
Much of programming is concerned with referencing and cross-referencing. In the usual programming systems, names of variables and arrays, labels and program sections are all in text form, and cross-correlated by compilers and other programmer resources like MAKE.
In other words, because ordinary programming lacks an intrinsic structure of connection, the structure of connection is managed by a variety of conventions and utilities that have to be too complicated.
However, since ZigZag has an intrinsic structure of connection, it should be possible to skip most of that cross-referencing and maintain connections between program parts directly. For instance, there may be relatively little need for variable names or labels.
ZIGZAG MAPPING IN GENERAL
Any structures and concepts can be mapped to ZigZag. However, here is the problem: there is no guarantee that mapping separate concepts to ZigZag will yield consistency or clean overall design. Choosing these mappings is an intricate task, aesthetic as well as conceptual. Making the ideas fit together consistently, reasonably and compactly is a constant struggle. We pray for elegance, but consistency is the first concern, and then the problem of *too many tempting mechanisms.*
Another key problem can perhaps best be called "overcrowding". You want to be able to remember and visualize the structure, without things being too close together; without too many exceptions; and avoiding if possible similar-but-different cases.* Overcrowded systems are hard to visualize and synopsize mentally or grasp quickly. Overcrowding is not the same as overloading in object-oriented programming, but it is definitely related. Some overloading is overcrowding.
* Some systems which are quite admirable and important are overcrowded in this sense. Two examples which spring to mind-- at least in my aesthetic judgment-- are APL and regular expressions in Unix, being powerful but quite difficult to use.
ZIGZAG MAPPING OF PROGRAMMING CONSTRUCTS
All the above remarks about general ZigZag mapping apply to programming. The design of zz programming constructs give us the same problems of consistency and cleanliness.
Any forms of programming system can in principle be mapped into ZigZag, giving cells the function of any possible programming constructs. We could have stacks, parentheses, Polish and Hungarian notation, message passing, and anything else.
But I don't think we want to.
PROPERTIES I HOPE FOR IN ZIGZAG PROGRAMMING STRUCTURE
Several ideas seem to me important--
ease for beginning users
building from the Chug method of selecting options
(discussed below)
embeddability of numerical results in text-- indeed,
no particular distinction between text and spreadsheet
and, far from the usual issues of ease for beginners,
easy parallel programming.
PROPOSED PROGRAMMING CONSTRUCTS
Some very simple programming constructs specially appeal to me. The following constructs are from the original 1986 design, though with adjustments. One mechanism (Chug) I have left unfinished because no correct set of details for it has yet emerged.
Shorthand: "assigning dimensions" doesn't mean putting
cells on particular dimensions, since every cell is on all dimensions.
This is a shorthand way to say we are assigning particular ways of connecting
certain cells on particular dimensions. If a particular function
is assigned to two particular dimensions, then how those cells are connected
in *other* dimensions doesn't matter and is open to user choice.
0. ATTACHING OUTSIDE ROUTINES
ZigZag has been designed from the beginning for attaching outside routines to cells, which then take effect on the cell fabric. Program routines may be crated in regular computing languages. The principal issue is harmonization of the outside routines with ZZ structure. Some kind of API will be required.
1. CHOOSING OPTIONS / SHELL SCRIPTS
Command-line interfaces will not go away. However much we may want to control the functions of Linux with magic wands, the choice of options in the existing jungle will continue to be important; especially for rising users who want to learn a higher level of computer understanding (and possibly actually Learn Linux). In other words, since we will always have to deal with shell scripts, Unix utilities and the command line interface, let us try to make these more comfortable.
Currently there are only two ways of working with Unix--
either dumb selection in Xwindows (an imitation of the standard Mac/Windows
PUI) or full-bore typing of command lines with the hyphenated options,
which are incredibly hard to deal with.
This is where ZigZag can be most helpful. We can create a method of selecting command optiosns that reduces the confusion and massive confrontation of this standard command-line interface.
We can, indeed, treat ZigZag as a new kind of command shell, but rather than call it zzshell (an earlier thought), there can be great benefit from simply using ZigZag to manage command line options.
Shellscripts may of course be easily invoked from inside
ZZ by attaching them to cells. But the issue is option management--
how users may easily select and attach options to shell
scripts and other commands, without having to learn everything at once
how users can create shell scripts and their option
sets.
Here is a simple method that works by selection, without
the user having to remember or understand all the possibilities.
Textual Command Options
The following trivial skeletal example is all we have room for here, but it will permit the user to select and manage text options in a command-line type of environment.
Consider that in the Unix command-line environment, the user must become familiar with many different options. But a user learns these options one at a time.
Very well, how can we create a setup that allows the existing knowledge to be used easily, and does not inundate with other details?
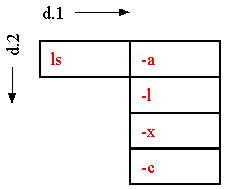
Suppose a new user is slightly familiar with four options for the command "ls". Let us show the user the command "ls" followed by the four familiar options in a corner list, as follows:
As shown, the option "-a" is selected; if the user executes the "ls", then the effect will be to execute
ls -a
But how can the user select another option?
Selecting options on d.1 and moving through them with Chug
"Chug" (not implemented in the xanadu.com prototype) is a structure command which moves a rank relative to the rest of the world, breaking and remaking connections appropriately. We show it here working with a vertical column.*
*Using Chug in forward-or-back mode provides principled substitution of individual cells, but doesn't show their origin or context.The user marks the column--
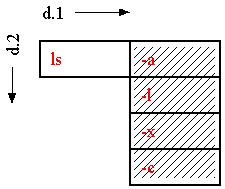
and then performs a "chug" operation, so that the "-l"
option comes into position:
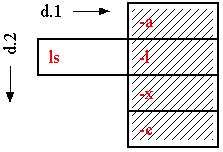
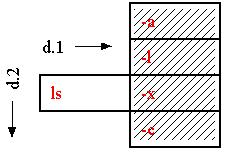
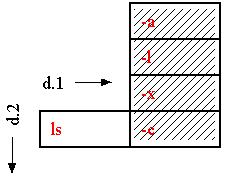
That's okay; the user simply looks along d.comment (or some other documentation dimension) for the explanation of each option.
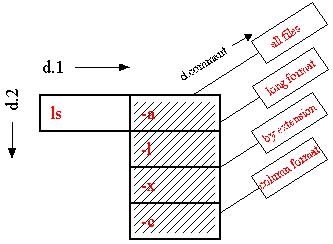
When the user has chosen an option, an ENTER command executes "ls" with the selected option, or alt-Enter adds it to a shell script.
(What about combining command-line operations? The experienced Unix user doesn't say "ls -a -l", but "ls -al". Well, this interface is not for that level of user. But extending that same interface will allow the user to put several options in a row, concatenating cells for the equivalent of:)
ls | -a | -l
Nested option selection. This method can allow options within options within options. We will not cover that here.
Design decision:
This idea of options
in d.1 is a KEY PART OF THE DESIGN.
We generalize from
this idea of options in d.1 to the notion of putting programming arguments
in d.1.
Options and operands
should be posward on d.1 from the command they modify or supply with parameters.
This will be generalized
to subroutines, below.
2. THE EXECUTION DIMENSION (d.xeq)
It would be nice for beginners if programming could proceed on d.2.
That way all you would have to do is type (or clone) a column of commands and their arguments, and then set them going.
This was part of my original model. Unfortunately I think it doesn't fit well with some of these other decisions. It would tend to overcrowd dimensions d.1 and d.2.
It is fundamental to the overall ZigZag design that we recommend d.2 for standard common lists.
That would mean some difficulties if we use d.2 for both
sequential program execution and common lists. For instance,
You might want to make a list of subroutines
which "need work".
If putting them in a column on d.2 affected
their order of execution, it would be impossible also to list them in this
manner.
Thus we need to be able to connect program parts randomly
on d.2 without affecting their execution.
Design decision:
Execution sequencing
should be restricted as much as possible for the sake of a clean mental
model.
The principal dimension
of execution will be d.xeq, which is created for that purpose.
Program execution
proceeds posward on d.xeq.
This is a choice
made to fit in with some of the other ideas here--
subroutines visible
in d.2 with arguments in d.1.
We generalize d.xeq,
however, so--
it isn't just sequences
of operations.
In particular,
we generalize it for nested subroutines (see below). (Of course,
nested subroutines are still sequential).
We also generalize
it very simply for parallel programming (with d..xeq-parallel, discussed
later).
Alternatives, someday
There of course could be many other possibilities, and
these can be explored in coming years--
We could try to make d.2 both sequence of execution
and ordinary listing. I think this overcrowds the ZigZag design.
We COULD have an order of execution among dimensions,
but that way lies madness. It's orderly but probably not visualizable.
(Maybe somebody will do it sometime.)
3. SANDWICH SUBROUTINES
Sandwich subroutines are a particularly simple form of nested visualization. (In order to help the user organize programs in this way, simple editing routines will be provided.)
To begin with, a subroutine may be shown as a dispatch cell and a return cell, which we recommend listing in d.2 as follows--

Only one dimension is labelled because these two cells would appear the same in any horizontal dimension.
This allows subroutine cells to be interestingly nested on d.1 and d.xeq. To see the nesting structure you look at d.xeq:
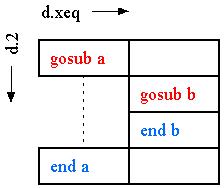
(The empty cells are filler cells of some kind.)
This allows a very nice cursor-controlled expansion down to any level of nesting--
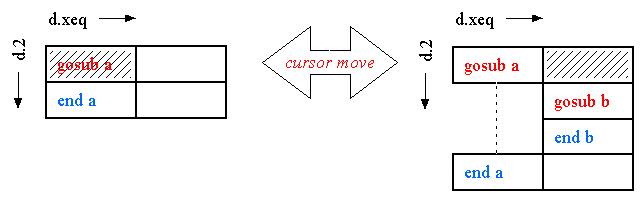
But what about the subroutine's arguments? Let us attach them to the gosub cell, posward in d.1.
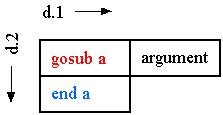
Why options and arguments should be in d.1
Design decision:
Options and arguments
should be in d.1 because:
They are psychologicaly somewhat like standard fields
of a record (another recommendation)
Non-executable lists fall naturally onto d.2
Lists of alternatives fall naturally onto d.2
Miscellaneous points about this visualization
In d.1 we may see subroutines as calls with their arguments. But separate subroutines are not nested and may be just listed *in any order*.
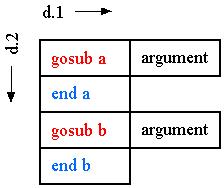
The only strong recommendation is that the gosub and the
endcell be consecutive in d.2.
SEEING NESTED ROUTINES WITH THEIR ARGUMENTS
It is possible for us to see the nesting AND the argument structure if we simultaneously view three dimensions.
Without special hardware, we can see three dimensions simply by assigning different angles to different dimensions. Then we can see all three dimensions: d.2 and d.xeq showing the nesting structure, and d.1 showing the arguments at every nesting level. (Depending on cursor position.)
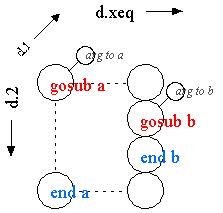
Note that the endcell doesn't *have* to be connected to
its gosub in d.2. This connection between gosub and endsub is to
support this visualization.
WHERE SHOULD RESULTS GO?
The design question is, where should we put the subroutine *results*?
Clearly into result cells, which can be of the same type we use for spreadsheet functionality. Presumably they can be put anywhere and cloned anywhere. But how can they be most naturally connected to this structure?
We could try to fit them into specific arrangements on d.1 or d.2, but that could lead to overcrowding of d.1 and d.2.
Design decision:
Results go to a
result cells connected to subroutines in the *result dimension*.
[formerly d.trigger; name not final]
Where the result goes
can be plainly seen along d.result. There is no need to try to fit
it into particular arrangements on d.1, d.2 or d.xeq.
The execution of the
subroutine triggers a result in the same way as editing a connected cell
in our spreadsheet-type model.
The recommended form of organization for subroutines is
therefore--
placing the subroutine's
arguments posward in d.1 from the gosub,
listing the gosub
and end in d.2,
nesting the subroutines
in d.xeq.
THE REASONS FOR THIS ARE SIMPLE:
it grows from the
command-line options already discussed for d.1;
it matches the general
concept of d.1 as holding fields and segments;
it matches the concept
of d.2 for common listing,
it lets d.xeq be
the execution dimension;
it provides clean
visualization as shown.

Users are therefore *invited* to follow this subroutine format as presented here, but they are under no obligation to. However, we will try to provide editing functions which support this.
Overloaded Intersections
(The fact that more than one cell may be at an intersection--
allowing a variable number of input arguments and a variable number of
results-- should probably not be exploited until we have views which show
this clearly.)
4. THE VINK
A Vink is an executable or functional strip of cells.
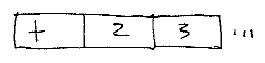 d.1
=>
d.1
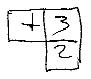
=>The idea is that these three cells are considered as an inseparable unit (being locked e.g. by preflets) and they may be executed as a whole. (Vink is short for "vinculum", a horizontal line in algebraic notation.)
When the vink is executed, a result occurs. In the vink shown, the operation + is attached to 2 and 3. (How to vary this will be discussed below.)
The design question is, where does the result go?
The logic is the same as for the subroutine results, above.
Design decision:
A result is connected
to a vink (presumably its negmost cell) in the result dimension.
[formerly trigger dimension; name not final]
Ranks and strips of arguments
Here is a sketch for another kind of executable vink:
 d.1
=>
d.1
=>
But here we have left something out. It makes no sense. Obviously we want to add these up; but there is no principle so obvious as the horizontal arrangement of arguments in the first vink. What do we do?
For this we will need an operation that moves the cells
up in a program loop.
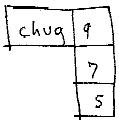
5. THE CHUG OPERATOR (a Design Problem)
This is one of the reasons I thought of the Chug operator, which expands the uses of the Chug option selection method shown earlier:
 d.1 =>
d.1 =>
Chug is a stepping operator. Each time Chug is executed, the column rises. When you execute the Chug, the indicated rank moves perpendicularly by one cell. Execute it again, it steps once more--
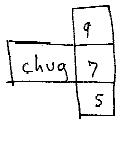
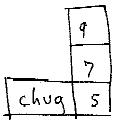
(Note that Chug is more general than just a programming construct: it is an important general structural operation still missing from the ZZ prototype. It is a complement of Shear, which moves two halves of a structure by one cell; Chug only moves a single column.)
(We can also create an infinite Chug loop--)
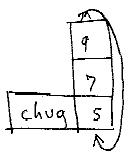
Now combine that with the + operator (IN SOME AS YET UNSPECIFIED WAY), and we can get a loop something like this:
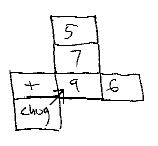
The idea is that the chug operator is applied to the column, it moves down, the + operator occurs again, Chug occurs again, and we reach a final state--
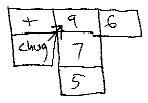
where the Chug won't work again.
This terminal state could be what stops the loop. There are other possibilities, such as a TEST vink in the column as well.
Uncertainties and problems in the design of Chug
This is unfortunately only a sketch for what the Chug operator should do, because there are several possibilities of how to define it.
Note that Chug is inconsitent with locked Vinks (as originally specified in the vink model above).
What connections break and remake?
PRESUMABLY the connections which Chug breaks and reattaches are within the dimensions of a current 2D view. (Remember that all dimensions are perpendicular to its movement, so we must be very clear in specifying which dimensions are to be broken and remade.)
Other Chug component ideas.
The movement of an unmarked strip by Chug must stop if existing connections would need to be broken--
However, if a strip is marked, this would then allow Chug to break and remake all connections along the marked strip--

What connects Chug to its target strip?
Presumably there should be a Chug dimension. This allows a given cell to be a target for chugs invoked by more than one chug cell for nested loops:
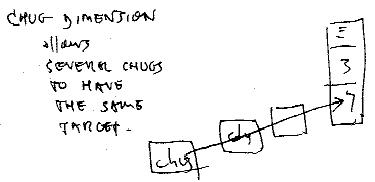
A pointer alternative to Chug
Because of the remaining uncertainties of Chug, maybe we should find something a little clearer.
One alternative would be to remove the Chug structural operation (which is intended to be the complement of Shear) from the list of desired programming constructs, and redefine instead a similar function which would step *a pointer* one element in a list, without remaking the ZZ fabric:

A simple mechanism allowing parallel programming (esp. fork, join and multithreading) can be provided easily by a second co-dimension, tentatively to be called d..xeq-parallel.
However, different parallel processes can have inconsistent consequences. ZigZag has, in principle, a global data fabric on which contradictory operations could be simultaneously ordered. The issue is how to assure consistent consequences in the ZZ tissue from different parallel proces.
The likely solution is to restrict access among processes.
This is what is ordinarily done with file lockout in conventional systems.
However, since ZZ has no files, working out a suitable convention in the
ZZ data fabric may be difficult.
7. THE CONTAINMENT MECHANISM
We have already implemented one extremely powerful programming construct in our prototype. That is the containment mechanism, which we may call zz-containment. It works by interpreting two dimensions of containment and simulating the contained behavior of other cells. The problem is that zz-containment may be too powerful. It is hard to visualize and its consequences fan out widely.
We have already demonstrated the execution of a clone contained in another cell (by zz-containment, which works by interpretation).
Its interaction with other programming mechanisms may be too hard to understand and visualize.