Doclist and Prosedoc
The Xanadu* Model:
A Pictorial View of Referential Documents and Content
Linking
*"Xanadu is a registered trade and service mark of
Project Xanadu, Sausalito CA 94965, USA.
The Xanadu model is described in various places, most definitively in *Literary Machines* (1987 version and later) and most recently "Xanalogical Structure: Needed Now More Than Ever" (at http://www.xanadu.com/XANASTRUX/XuSum99.html).
What follows is independent of implementation. In the ZX system we will be implementing this model with ZigZag cells as the underlying mechanism.
Premises of the Xanadu model:
• Documents are often connected side by side in parallel and need to be viewed that wayStructure of the Xanadu model
• Links should be to content, independently of where that content moves to among versions and documents
• Many simultaneous links may be on the same content
• Identities should be kept track of automatically (transclusion)
Therefore
•• links survive changes •• origins may be seen •• special copyright solution •• etc.
• Actual data content is in permascrolls (append-and-read-only, sometimes called write-once)SEQUENTIAL TEXT, A SPECIAL-CASE BUILDING BLOCK FOR CONNECTION
•• All data has permanently-assigned addresses (permaddresses)
• All use of this data is referential or simulates referential usage
•• We manipulate the data only by pointers
•• When the data moves among machines, the apparatus of referential use (e.g. permanent addresses) moves with it
• Links are to the permaddresses of the content
• Comparison of permaddresses manages--
•• link following
•• transclusion• The operative unit is the *version*, represented by a version list. (To simplify explanation, we also say "prose document" or prosedoc, represented by a *doclist*.)
•• A "document" is all the versions with the same name and owner, or some subset of versions designated by the owner
• Documents have arbitrary structure which is not necessarily hierarhical, may have overlapping contents.
• However, a special case is the simple prosedoc (below), which also provides connected text to the richer document structures.
Connected sequential text in the Xanadu model is a commodity which can be streamed, texture-mapped, etc., with all its connections available.
We will give a visual example here, using the simplest
sequential text and showing how to connect it.
Prose documents (prosedocs), prose versions, and commodity text
A prose document is the simplest form of document, corresponding to a conventional textfile, *without special fonts*. (For anyone in doubt, "prose" is the form in which the *New Yorker* magazine publishes its articles-- without italics or boldface.)
(We also use the term *version* for this same structure.)
Doclists, versionlists
A prosedoc or version is represented by a sequential list
(doclist or versionlist) of its successive contents, which is a list of
pointers to the actual contents.*
*(The
term *vlist*, version list or virtual list, is used in xu88, and *vscroll*
has also been used in some of the ZX documents.)
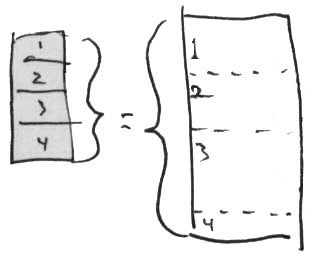
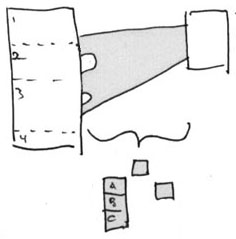
Doclist and Prosedoc
In this illustration, we show a prose document of the text itself on the right and the doclist of content pointers on the left.
These two are essentially equivalent, in that the doclist perfectly represents the prosedoc.
(At the user interface level, it should be possible to edit either one and have the changes reflected in the other.)
Permascrolls
A permascroll is where the actual text and data contents are archived. It is an append-and-read-only sequential repository of the actual contents, in principle of unending length. (How this is mapped to existing file systems is an implementation issue.)

Permascrolls of different data types
At the time of arrival of data in a user's main machine, it acquires a permaddress. We may call this *registration* of the content.
Doclist and Permascroll
The doclist points to addresses on permascrolls.
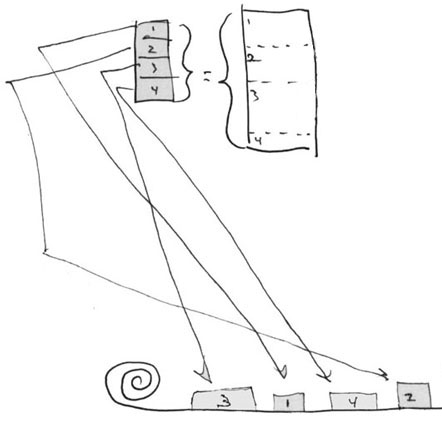
The document illustrated above is made up of four pieces,
shown as refpointer sequence 1, 2, 3, 4. This sequence is their current
edited sequence; it is not the original order in which those portions of
text they arrived on the permascroll.
Content Linking
In the Xanadu model, links are to contents and between contents. (Note that this was our original usage of the word "link", but the Web changed the meaning of the term. Hence we now say *content link*.)
Here is a link between two prosedocs, which we will call the left document (document L), and the right document (document R).
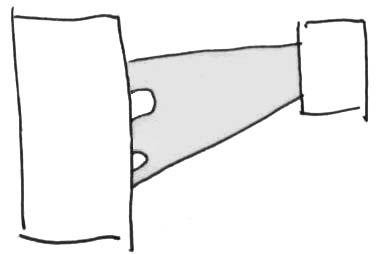
Link betweeen two prosedocs, with intermittent spanset
on the left
The illustration shows a content link which connects three spans on the left prosedoc (document L) with one span on the right prosedoc (document R).
Let's say that Document R is a published comment about document L. The funnily-shaped stripe between them is the comment link. The author of document B is making one overall comment about three sections of document A.
As can be seen from the illustration, the link is between a collection of contents on the left and a collection of contents on the right: it is between the three portions which it touches in document A and the middle three-fifths of document B.
We want to be able to follow this link in either direction, and do various other things.
Storage of the documents
First we must consider how the two documents are stored. (We'll ignore the link for the moment, and consider the body of the text of the two documents.)
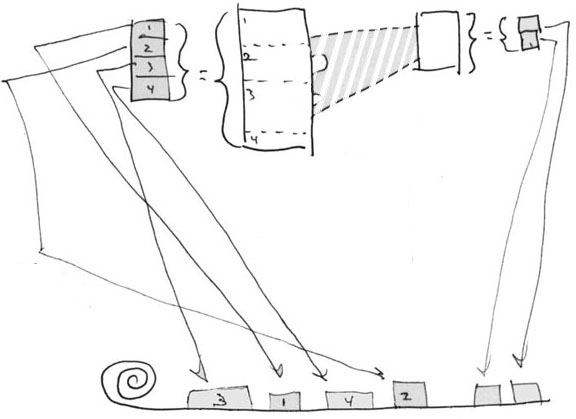
Document L, as already shown, is made up of four pieces in sequence 1, 2, 3, 4. And document R is made of two pieces which are elsewhere on the Permanscroll.
Representation of the Link
Now let us consider the link between them. The link is itself addressable; thus it is a unit with an address (in the ZX system, its *handle*). The link connects two ranges of contents, and thus it has two lists, the contents on the left and the contents on the right. These are the endsets of the link.
Link as represented by a handle, two lists and a type
(not shown)
It also has a link type (not specifically shown), which is in this case the link type "comment".
Resolution to Permaddresses
The link is shown connecting to three virtual spans on the left document, with refpointers designated A, B, C in the link's left endset list. These initially refer to relative content positions in prosedoc L.
Note that in this case the boundaries of the separate spans A, B, C of the link endset do not correspond to the boundaries of portions 1, 2, 3, 4 of prosedoc L.
However, we must always resolve such references to their actual permascroll addresses, especially to avoid reference loops and other indirection traps. The result appears below.
Let us look at all these relations in one overall diagram of the two prosedocs and the one link between them. (We concentrate on the left document and the left side of the link):
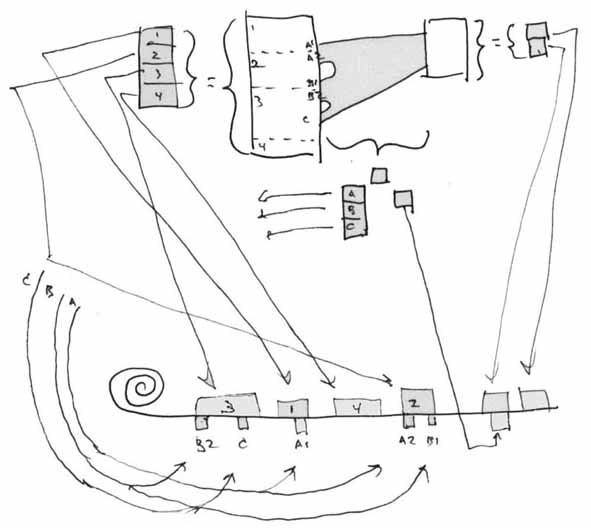
This shows the how the addresses of the link endsets overlap the addresses of the referenced portions of document L
We have resolved the left list of the link (originally A, B, C relative to positions in prosedoc L) into pointers A1, A2, B1, B2, and C, which reference the actual separate permascroll addresses of the portions of content 1, 2, 3, 4.
As shown in the illustration, endpointer A resolves to A1 connected the end of portion 1 and A2 connected to the beginning part of section 2: endpointer B resolves to B1 connected to the end of portion 2 and B2 connected to the beginning of portion 3; and C, connected to the middle of portion 3.
WHAT WE CAN DO WITH THIS STRUCTURE OF CONNECTION
This structure is the same in xu88 and ZX. Regardless of the implementation, here are things we can do with this structure.
1. Inclusion in the document
• considering any byte on the text permascroll, we may
find out whether it is in document L by searching L's list for its address.
• considering any byte on the text permascroll, we may
find out whether it is in document R by searching R's list for its address.
2. Transclusion checking
• we may check whether the same contents appear more than
once in the same document (self-transclusion or transcluded copy)
• considering any byte on the text permascroll, we may
find out whether it is in both document L and document R. (In this
example none are in both.)
• to find all the transclusions between two prosedocs,
we consider what spans of addresses they have in common.
• to find all the transclusions between two windows on
a screen, we consider what spans of addresses they have in common.
3. Link following
The process of link following is far richer than with HTML:
• from any byte on document L, we may find whether or
not it is linked to document R, and we may find all the bytes to which
it is linked on document R.
• from any byte on document R, we may find whether or
not it is linked to document L, and we may find all the bytes to which
it is linked on document L.
All these processes involve comparison of addresses, and
more particular finding address spans in common between lists. The
efficiency issue is of course how to find *all the spans in common* among
these sets.
CLASSICAL XANADU
It was to find these address-span overlaps that classic Xanadu software (xu88, now Udanax Green) was developed. Its search facilities are particularly designed for large-scale parallel queries of this type.
In xu88, all objects are given an address in an expandable
tree-structured address space called tumblers. These include--
• servers (nodes)
• user accounts
• documents
• versions
• elements •• bytes •• links
A tumbler span defines a range of addresses within the linear representation of this tree.
Through the use of matrix operations on tumbler spans,
the xu88 software manages this address space efficiently. (Code is
available at udanax.com; see explanation at http://xanadu.com/TECH/xuTech.html)
TUMBLER ADDRESSING
Permascrolls and cells should be assigned unit types for tumbler addressing, in order to assure compatibility with Udanax Green (formerly Xanadu 88.1).
•