xuGzn-D19
===07.04.19
Toward a Deep Electronic
Literature: The Generalization of Documents and Media
Theodor Holm Nelson, Project
Xanadu and Oxford Internet Institute
Intellectual Property Notices:
Transliterature(tm), or TransLit(tm), is intended as an open standard, but
these names are claimed as trademarks to avoid semantic drift. Xanadu(R) and
ZigZag(R) are registered trademarks. "Xanadu Space" and "Xanadu
Transquoter" are claimed trademarks.
SUMMARY. We
propose a generalized representation of media combining text, audio and
video in parallel format, with overlays and connection to content
origins. This is intended to handle all the usual functions of text,
audio and video, while offering many more functions and
visualizations. It offers, as well, a unique copyright
solution.
We live in a world of documents and
media. They affect us all, all the time-- culturally, emotionally,
cognitively.
But what should be the design of
documents and media in the digital age? Since the advent of the
computer, thousands of ideas have been advanced for the design of documents
and media. These ideas come from everywhere-- office traditions,
recording and movie traditions, computer traditions.
DIGITAL MEDIA NOW, AND THEIR TRADITIONS
Today we see a wide variety of
disparate and unrelated media formats and mechanisms, imitating the
past, largely based on tradition. These traditions have given us special
cases unrelated to each other and imitating the past, with separately limited
possibilities.
OFFICE
TRADITIONS
The main tradition from the
office world is paper simulation, as developed at various places (notably
Xerox Palo Alto Research Center) in the 1970s. Few have examined the
assumption that paper is the correct model for holding written
content. But today's simulation of paper is only partial: they left
out a key property of paper. Unlike sheets of real paper, you can't
write comments in the margin! Or cross things out! Today's
principal text systems-- Microsoft Word and Adobe Acrobat-- simulate
paper under glass.
RECENT TRADITIONS OF
MEDIA
In digital media we still
imitate the past and its conventions, just as early car-makers put a socket
for a whip on the early automobiles. We imitate the past, rather than
considering the future possibilities--
Imitation of
Recordings and Radio. Today's digital audio packages
(mp3s, podcasts) imitate previous conventional recordings and radio
programs. They are basically named audio files that allow you to go
from beginning to end of a prepared presentation-- with no branching, no
looping, no dynamic selection among multiple
tracks.
Imitation of Photo
Layouts. Today's photo layout systems are based on
imitating conventional 2D sheets. Each photo has a set "size," even
though a photograph intrinsically has no size except the paper it's
printed on.
Imitation of
Movies. Today's movie editing systems are based on shots
seen as individual frames. Today's digital video and movies are
simply imitations of existin non-branching films. (There are
exceptions, such as "additional content" on CD-ROMs, but they tend to be
weak and clumsy.) There is no branching, annotation,
rearrangement.
COMPUTER
TRADITIONS
Hierarchy. The
principal tradition in the computer world is the simulation of
hierarchy. It is generally believed that hierarchical directories
(more recently called "folders" are the right and true way to
organize content and structure on computers, and few alternatives have been
tried. Users, however, don't relate well to hierarchy. Desperate
variations are being tried by software designers, but no one is questioning
the basic correctness of this model, except the author and his
associates.
Embedding.
Embedded markup-- scrambled-in coding-- has become the standard way of
labelling and marking digital content, from word processing to the World
Wide Web. But embedded markup basically tangles the content and defies
re-use. The alternative is to use overlay formatting, which refers to
content but does not alter it. But the alternative of overlay markup
is rarely tried.
HYPERTEXT TRADITIONS--
One-Way Links and Jumps
The tradition of "hypertext"
has become a tradition of one-way links and jumps. That's because
everyone's notion of hypertext is now the World Wide Web and its
structures. The World Wide Web has only one-way, non-overlapping,
nontyped links.
[PIC: 1-way links, no types, no
overlapping allowed
Fig. A: One-way, non-overlapping
links
This is because the World Wide Web was
based on trivial, convenient mechanisms rather than deeply designed.
The embedded one-way links were easy to implement. They then allowed
this casually-chosen mechanism to determine the literary properties of the
system.
This approach-- one-way,
non-overlapping links-- is now the way people think of interaction,
hypertext and interconnection.* But far more is
possible.
* In a letter to New
Scientist in 2006 (1),
I apologized for any part I may have had
in the creation of this structure in the
nineteen-sixties.
THE LITERARY TRADITION
I propose that another tradition
is deeply relevant: that of literature, which has a somewhat slant from
other media.
We usually think of literature as
referring to books and other paper publications, sometimes the sum of all
paper documents.
The purpose of documents and
media are to present contents to the heart and mind, and thus to affect human
experience and understanding.
UNIFICATION of
Literature
Literature is a unifiying
system. All books fit on shelves. Books can be read side by side
and at the same time.
Literature's AVAILABILITY, OWNERSHIP, RE-USABILITY,
ANNOTATION
Literature stays
available. Books can be sold, put in libraries, inherited, repeatedly
cited and quoted.
Whereas other media, like movies and
radio, have had restricted availability. In past times a radio program
went by once and was gone; a movie played in a theater and was rarely seen
again. Until recently there was no personal ownership, restricting
what was available.
Now that we can own recordings and
videos; they become more like books in their
flexibility.
Literature's CONTROL BY THE USER
Book and reader form a
bond. The reader can control the book, read it in any order, turn
pages or skip ahead, keep it on shelves with related or unrelated
documents. The reader may turn the pages as desired.
Whereas the movie-viewer in a theater
must sit through every scene, regardless of boredom or irritation.
(The movie-viewer at home is more like a book reader, able to skip backward
and forward if watching a tape, though more restricted if watchig a
DVD.)
EXTENDING THE LITERARY TRADITION TO ELECTRONIC MEDIA
The Xanadu(R) Project, begun in
1960, has been intended to create a deep on-line literature, extending the
previous kinds of literature in the most powerful ways we can find. But
it must also be fundamentally simple, making sense to authors and
readers.
On-line documents should all have the qualities we know from
paper literature--user control, re-usability, long-term availability without
restriction, use of documents together. Presently electronic media do
not offer these basic amenities.
However, I propose to expand the term "literature" to a
larger sense, to find the most powerful abstraction and generalization of
literature (2).
I would like to use the term "document" for any media package
or construction that uses media components (text, audio and/or video); and
expand the meaning of "literature" to the sum of all media
objects.
The reason for conflating them in this way: I believe they
cannot and should not be separated, either philosophically or in the design of
tomorrow's documents. Paper documents, radio programs, films and video
all cover the same subjects and belong together.
In our work, the idea has been to
implement the concepts of literature in this extended sense,
extending
- user option and choice (as
in flipping freely through the book)
- long-term availability
- joint use of documents together
- arbitrary and unlimited
linking.
- quotability
and re-use
This
last is our most ambitious generalization, transclusion:
generalizing quotation into visible quotation and permitted, unlimited
re-use.
But before we can consider how things
should be, we must first consider the way things are: the limiting conventions
that so far have prevented generalization of media structure.
CURRENT COMPUTER
CONVENTIONS
The computer field has been
built gradually on conventions, one after the other, all seeming plausible and
even necessary.
1.
FILES
While there were computer
files as early as the 1940s, the structure of today's files and file
mechanisms was essentially crystallized by the Unix design in
1970.
- hierarchical files and
directories as the principal units known to the file system
- managed by a master table (inode
table) of pathnames
-
file as an opaque data package, contents ignored by operating system
[except for strange #! convention in Unix]
- internal units inside file not recognized by
filesystem (all management of internals is left to
Applications)
- file
content types recognized:
-- characters
(ASCII)
--
binary
--
application-specific
- content brought into a file loses all identity and connection to
origin
-
"metadata" only on files and directories, and only of a few standard types,
especially:
-- data type (associated
application)
--
filename
--
permissions
--
(Size)
--
lock
- metadata types are rarely extensible
- internal units and content are allowed no
metadata
- internal
units and content cannot be independently protected
- version management is left to the user or the
application
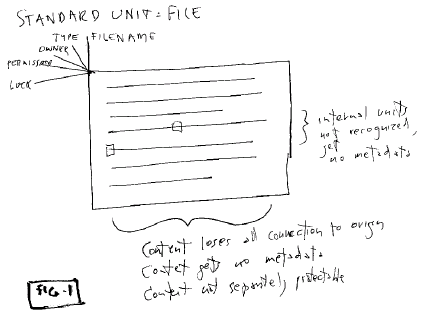
Fig. 1: A file, the standard
unit
Document as file. The most remarkable convention
is that
one document must be one
file.
This unexamined convention results from
the traditions of opaque files and paper simulation. It drastically
limits what documents can do or be.
It means that
- links can only point
outward, because they must be contained within the file
- relations to other documents must
be maintained with difficulty by the user, "outside the
application"
(It
also determined the structure of the World Wide Web.
)
2.
APPLICATIONS (AND THEIR PERNICIOUS MOTIVATIONS)
"Applications" determine the
user's working world, but their conventions are rarely
examined..
(Again, let us consider Unix (1970) to
be the starting line.
Unix users were assumed to be
programmers, with suites of utilities and pipes to run their data
through.
With the growth of personal computing,
however, this changed. A class of "users" appeared, who couldn't
program. Instead they were given "applications." Today's
conventions of "application" were created at Xerox PARC, first productized
with the Macintosh in 1984, and then built by Microsoft into its Windows
operating system.
Applications were designed
to
- accomplish specific
functions chosen by each software company creating the
application
- ... with
arbitrary boundaries and powers chosen by each software company creating
the application
- lock
users into the manufacturer's program
- prevent programming except through permitted
"scripting"
- prevent
direct data access (and escape from the software
package)
These
application conventions
- allowed an application to
have its own windows, but allowed no visible connection between content in
one window and content in another
- locked a specific data type to a specific
program (inescapable in the early Macintosh)
- encouraged each manufacturer to create
opaque internal data structures to prevent compatibility
- allowed data transfer among
applications by invisible "clipboard"
- "clipboard" conventions limited to
recognized data types
While there have come to be agreed-upon file standards that can be
shared across similar programs (e.g. SYLK files for spreadsheet),
manufacturers are motivated to maintain incompatible differences and
extensions.
Thus there are no broad media
conventions within the software realm, except
- clipboard compatibility
between manufacturers of certain few recognized data types
- industry-agreed file standards for
certain few recognized types of data
Many well-intentioned parties try to create
compatibilities (e.g. the VLC movie player, continually updated to play all
new movie formats), but the widening number of differing software packages,
intentionally made different only for incompatibility, assures that this is
a losing battle.
THE FUNDAMENTAL ISSUES OF DIGITAL MEDIA
"Convergence," which was
predicted in the 1980s as the unification of media, has not happened.
Why not?
Today's digital media applications are
Balkanized and internally incompatible; partly because each is designed
differently in the face of these issues; and partly for deliberate
obfuscation. How can we unify them?
The term "multimedia" is often used for
such unification; but the term suggests that we're putting separate things
together, instead of uniting what should never have been apart. But to
unify them requires starting from scratch.
STARTING SIMPLE, THE COMPLICATIONS
GROW
So let us consider digital
media and the complexities of building them. This will show why there
has been such divergence of structure; and why different media modes are
difficult to unify.
Digital media start simple, acquire
layers of complication.
Let us begin from first
principles. What are the building blocks of media, and the
complications they must go through that add layers and
intricacies?
All of the following concerns challenge
conventional data structures.
LEVEL ONE: FUNDAMENTAL
CONTENT
The basic substratum is
flowing, countable media-- text, audio,
video.
LEVEL TWO:
UNITS
Media are divided into units
and subunits.
By convention in today's computer
field, only one level of unit is recognized by the computer. This is
the file, the unit of data. Any units inside a file can only be
recognized by an application. This is an arbitrary system of
constructs that few challenge.
Every form of data has its own
subunits, recognized only by its particular application. Microsoft
Word has its paragraphs, Director has its "cast" of "actors," spreadsheets
have their rows and columns and cells, and so on.
In other words, the outermost unit is
recognized by the system, but any units within units must be treated
differently. A file is allowed to have "metadata," but subunits and
contents are not.
LEVEL THREE: INTERNAL
ELABORATIONS
There are many things we may
want to do to digital media inside a work or package.
- selection
- annotation
- overlays
- connections
- relations, properties, attributes not inside
the units or content ("metadata," in today's terms, except "metadata"
usually refers onoy to entire units)
There is no standard way for these things to
happen or be represented in data.
LEVEL FOUR: EXTERNAL
ELABORATIONS
Many things need to happen to
digital media outside a work or package.
- inclusion from elsewhere,
recognizable re-use
-
side-by-side comparison
- linkage to other objects
- cross-indexing, cross-filing
(In the larger context of
information outside, where should a thing be? Should there be one
or many of it?)
There is no standard way for these things to happen or be
represented in data.
LEVEL FIVE: CHANGE AND
VERSIONING
The need to change files and
documents, recognized everywhere, has many consequences.
- successive stored versions
(unsupported change for most users)-- with home-grown version names,
numbers and designations
- version management in some applications, such as Photoshop and
Word
There is no
standard way for these things to happen or be represented in data, except
for
- file locking
- DIF files (supports line-oriented
versioning)
-
version-management facilities such as CVS (supported line-oriented
change)
The
kinds of versioning needed in the document world require rich
facilities. In the document world, we see many kinds of versioning and
problems related to them--
- Provisional documents (to
be replaced "soon")
-
"Final" documents
-
Post-Final documents (when the previous version wasn't as final as they
thought)
- Ongoing
documents (continually re-released for continuing use, even though they
keep changing)
-
Official documents (whether final or ongoing)
- Documents that "should not have been
released"
- Forking
documents (one document is changed to two different documents for
different purposes; later changes that should go into both versions are
hard to manage)
-
Frequent embarrassment and confusion as the wrong version of a document is
given out
- Frequent
embarrassment and confusion as the wrong version of a document is
accidentally revised
Version management systems should deal with all these
problems. But there is no standard way for these things to happen or
be represented in data.
LEVEL SIX: ALTERNATIVE
VERSIONS
Sometimes there needs to be
more than one version of a media object
- for different
purposes
- because
it's undecided, decision postponed
Examples:
Translations.
This is self-explanatory.
Different versions for different
markets.
Director's Cut. The
director of a film rarely gets his way; under certain circumstances he is
allowed to release a version edited to his liking, for example on
DVD. This is parallel to the regular version.
"Which headline?". At a
key moment in the film "Citizen Kane," a character holds up two front
pages of a newspaper and asks which one to run. They read: "KANE
WINS IN LANDSLIDE" and "FRAUD AT POLLS!" This happens all the time
in publishing: two versions are prepared and one chosen. (The
November 1960 issue of MAD magazine, released the day after the election,
said "MAD Congratulates John F. Kennedy"-- and, on the other cover, "MAD
Congratulates Richard Nixon".)
Combining change with alternative versions gives
us forking documents, documents evolving simultaneously along
more than one path.
A CHALLENGE TO THE DATA WORLD
Managing all of these separate
elaborations challenge conventional data structures. And, as already
mentioned, there is no common way to handle these issues across different
"media applications."
DESIDERATA: TOWARD A PRINCIPLED, UNIFIED, GENERAL
STRUCTURE
These varieties and
entanglements of file structure and media structure seem to me accidental and
unfortunate. We need a more general, unified approach that will alllow
deep re-use, interconnecting and combinations of media, and allow everything
to be cleanly included, selected, annotated versioned, etc. in the same
way.
It is for this reason, among many others,
that I and my colleagues have worked for so long to create better structure,
and we believe we have succeeded. The following lists the intended
aspects and features of such a universal media
system.
OBJECTIVES AND SPECIFICATIONS
The objectives and
specifications were set forth in the summer of 1979, as discussed in the
History section. The resulting xu88 design, now simplified as
Transliterature, endeavors to accomplish the following.
1. FORM OF
ASSEMBLY
We propose a single form of
assembly for fluid media-- text, audio and video-- and all their
combinations. These combinations may be far more varied than generally
suspected-- but because of the traditional models, the combinations have not
been recognized as possible, desirable or
legitimate.
2. UNIVERSAL QUOTABILITY AND SOURCE
CONNECTION
It must be possible to use
content taken dynamically from different sources and maintain connection to
those sources.
3. PARALLELISM
There should be a single
mechanism for parallel tracks and structures within and between
documents. (For example, annotation of audio and video by text, audio
annotation to text, annotation to text, etc.) This should build up as
desired to any complexity (multiscreen video, multiple narrative
threads)
4. ELABORATIONS AND "METADATA" ON ANYTHING
ll these aspects and features
should work together:
- units within
units
- units
recognizably re-used
-
flowing content within units
- units within flowing content
- contents recognizably re-used
- everything
selectable
-
everything connectable
- everything overlayable
- everything
annotatable
It
should be possible to overlay, select, lock, and annotate everything-- not
just files, but contents and subparts and subportions and relational
structures.
5. CHANGE MANAGEMENT
Change management and version
management should work uniformly across all these aspects and features-- not
merely the content layer.
This includes not merely backtrack, but
foretrack (going forward through changes) and sidetrack (going to a
different path in a version tree).
6. GENERALIZED
INTERCONNECTION
We generalize connections in
two ways:
Transclusion:
recognizable re-use, especially through visible connection to origins of
content.
Overlay structures
composed of individual relations (called variously clinks, or content
links; or flinks, floating links).
- any number of link
types
- links by
anyone on anything
-
unbreaking links
-
links weaving together to form designed
overlays
7. RE-USE AND
COPYRIGHT
Everything should be
re-usable, including copyrighted material.
- we should be able to see
re-uses of content
-
unlimited re-use without negotiation (of material from participating
rightsholders)
This should work within the existing copyright law and provide
payment incentive for the publishing
industry.
A TALL ORDER?
This list of objectives may
sound absurd, but it can all be achieved with a small and simple
structure. Paradoxically, this is far simpler than the collection of
mechanisms in general use.
It is, however, counterintuitive for most
people, and requires considerable
explanation.
HISTORY IN BRIEF
The detailed specifications were
laid down in the summer of 1979 by a working group in Swarthmore, Pennsylvania
(see Literary Machines).
The xu88 Design
A detailed design was developed in 1981
by Roger Gregory, Mark S. Miller and Stuart Greene. Because the targeted
finishing date was 1988, it was called Xanadu 88.1, or xu88 for
short.
It crystallized two types of connection
as a basis for hypertext. (This has recently been called xanalogical
structure (4).)
- deep n-way links that can be
overlaid to any depth and followed in two or more directions.
- deep quotations (or transclusions),
remaining connected to their origins.
The xu88 system was designed for maintaining
extremely large collections of documents and their connections, maintaining
them as they changed, and delivering them to on-line users through the FEBE
protocol. It was thus both a data management system and a server,
although the term "server" did not exist at the time.
With very unusual data structures (called
enfilades), xu88 was further designed to scale up across a network, with
peer-to-peer interchange (the BEBE protocol).
The Autodesk Venture, and
Since
In 1987 the Xanadu project was acquired
by Autodesk, Inc. Regrettably, the xu88 design was dropped, and another
design (xu92) was attempted. This design never converged, and Autodesk
dropped the Xanadu project.
In 1999 the uncompleted code for xu88 was
placed in open source, at Udanax.com, where it will be found under the name
"Udanax Green". (The code for xu92 was also in princple put under open
source, but it is encumbered with various rights issues involving proprietary
languages.)
Transliterary Structure, an Open
Standard
More recently, at the Oxford Internet
Institute, I have created a simplified version of 88.1 called
Transliterature (5).* It is an open data standard to be found at
transliterature.org. It is client-side only, for use with standard
servers and such protocols as http.
* Differences from
xu88:
- transliterature is a
data format, with implied behaviors for the programs that will use
it
- no special
server, except that portion service and flink service are
required
- no
enfiladic data structures
- no attempt to find all transclusions globally, only deals
with transclusions from known addresses
- xu88 built all relational structures
from dyadic links; Transliterature predefines a variety of relations
and templates
-
parallelism is an explicit
addition
Xanadu Space
We have been working on an experimental
client for Transliterature, called Xanadu Space. (Lead programmer:
Robert Adamson Smith.) This differs from previous xanalogical clients in
that it offers some remarkable 3D views of document
interconnection.
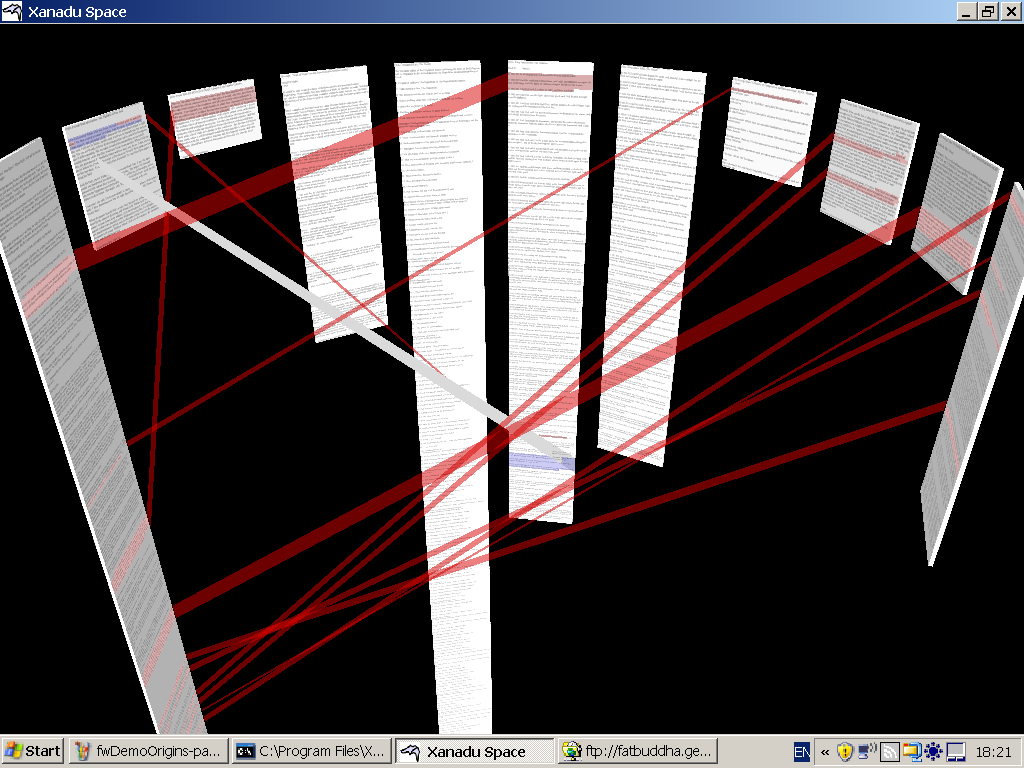
Fig. Z. Document
interconnection in Xanadu Space.
But the center of Xanadu Space is
Transliterary format. Transliterary format is what we will now
consider.
VERY BRIEF SUMMARY OF
TRANSLITERARY STRUCTURE
Transliterary structure may be
described very briefly, as follows:
A document is one or more strips,
each represented by a list of
pointers,
overlaid by labels and
relations.
Explaining it, however, will not be so
brief.
LESS-BRIEF SUMMARY OF
TRANSLITERARY STRUCTURE
Transliterary structure is best
understood as having several aspects:
1. Sequential
constructions of existing content,

Fig. 24: Sequences of
content
represented by pointers to the content
sources (local or remote).
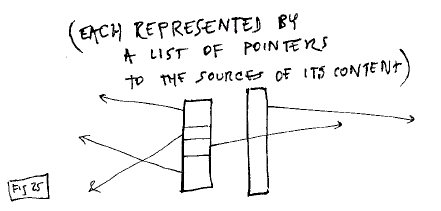
Fig. 25: Content is
represented by a list of pointers
2. Transclusion (content knowably
in more than one place).
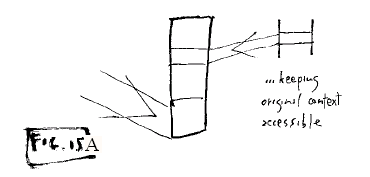
Fig. 15A: Content remains
connected to its original source
Connection to the sources is simply
maintained by the addresses in the content list.
3. Overlays, markers and links
imposed upon the content.
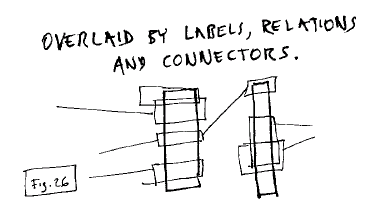
Fig. 26: Content overlaid by
labels, relations and connectors (flinks)
These are made with"flinks," or
floating links. These structures are not embedded, but are attached to
the contents themselves (actually locked to the original content addresses
in the outside world).
EXPLANATION OF
TRANSLITERARY STRUCTURE
While these descriptionis are in
a sense complete, they are probably not clear, so they must be
expanded.
I will also
endeavor to explain some of the system's ramifications and
benefits.
1.
CONSTRUCTIONS FROM EXISTING CONTENT
A transliterary document may be
built partly or entirely from pre-existing content. It may be made of
portions brought in from anywhere; contents can be mixed from all
over.
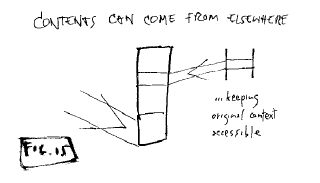
Fig. 15: Contents can come from
elsewhere
(None of the origin connections of the
content are lost, since the addresses remain
available.)
2. SEQUENCE PACKAGE
The visible default presentation
of arriving content is a sequential strip, track or package.

think
Fig. 16. Different views of
arriving sequential content
Depending on what is wanted, we can think
of it, and use it, as a
- sequence
- page
- strip
- strand
- track
- thread
- train
- stream segment
- piped data
stream
The content
sequence is given but may be overridden. By default, the arriving
contents are treated as sequential, but may be restructured by imposed
relations (flinks).

Fig. 5: Default sequence may be
rearranged
The content components may be seen as they are, or
combined and hidden, if the content package is
rearranged.
COMBINING
LOGIC OF SEQUENCE TRACKS
This structure supports
unlimited parallelism.
Tracks may be assembled into parallel
sequences, shown as pages or plexes as required. This generalizes the
parallelisms of various media: text columns, text marginal notes, audio synch,
etc.
A document may consist of any number of
sequential strands of media. The strands may couple sideways through
transclusion or flinks. This facilitates--
- outlines
- indices
- commentaries
- multiple musical tracks,
- etc.
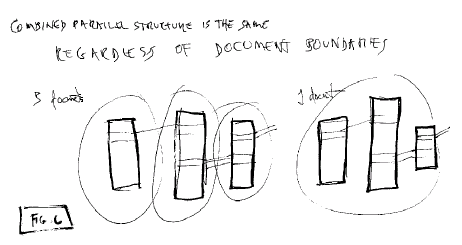
Fig. 6: Parallel structures are
independent of document boundaries
The identical parallel structure may be
within a document or combined among several documents. It doesn't matter
where the "document" boundaries are, the structure is effectively the
same. The same structure can be created by one person in one document,
or by many people doing separate tracks in different documents. The only
difference is document boundaries and ownership.
3. DOCUMENT
A document consists
of
- 1 or more sequence
packages
-
and/or
- 1 or more
flinks.
In other
words, a document may consist of as little as one sequence package or one
flink.
4. HOLLOW
REPRESENTATION: THE EDL
The transliterary document is
built of content portions that may come from anywhere. However, the
content itself is secondary in the data management operations. The main
representation of a document is in hollow format, without content. The
content may be sent for separately.
We call this hollow format an EDL.
EDL stands for "Edit Decision List," which is a standard Hollywood term for
what media elements to take, and in what order. Thus an EDL is a plan
for what contents to bring in and how to arrange them.
The term began in video editing: when you
start with reels of videotape and decide what shots you want in the order you
want, the result of these decisions is an Edit Decision List, or EDL. To make
the actual final video, the EDL is fulfilled by copying the individual shots
that have been specified.
We are using exactly this meaning, except
extending the EDL to include text and audio as well. Any document,
movie, or other media object may be specified or assembled by a Transliterary
EDL.
A new EDL standard?
There is no standard EDL system because each manufacturer of video equipment
has their own.*
* A noble attempt by Avid
Corporation to create
a
universal EDL format appears to have lost steam.
We like to think that our proposed EDL method
might be generalized to a standard usable by all industries. However, that is
not our main thrust at the present time.
Parts of an EDL. A
document is maintained in an EDL as
- a content list (a list of
content portion addresses)
- a list of flinks (relations and overlays)
- all the native flinks (those flinks
originating in this document)
Note that a minimal EDL can be simply a list of
content spans, without flinks, as in FIG. B.
The content list. The
list of contents is specified by the addresses of the content.
- Each content element is a
span within a source page or file.
- the span has a starting position (0-base
count, as in C) and a length
- the span is in terms of
"permaddresses"
An
example of a content list (which can be a minimal EDL) is shown in FIG.
B.
http://tprints.ecs.soton.ac.uk/archive/00000005/01/seclife.txt?xuversion=1.0&locspec=charrange:1942/879
http://tprints.ecs.soton.ac.uk/archive/00000011/01/zifty-d9.txt?xuversion=1.0&locspec=charrange:3348/201
http://tprints.ecs.soton.ac.uk/archive/00000005/01/seclife.txt?xuversion=1.0&locspec=charrange:3292/298
http://tprints.ecs.soton.ac.uk/archive/00000011/01/zifty-d9.txt?xuversion=1.0&locspec=charrange:3835/107
http://www.xanadu.com.au/transquoter/?xuversion=1.0&locspec=charrange:14/22
http://www.xanadu.com.au/transquoter/dlitClientSpec-D9.txt?xuversion=1.0&locspec=charrange:554/27
Fig. B: sample content
list, a minimal EDL
If these portions are sent for
("dereferenced"), we get the document in FIG. C.
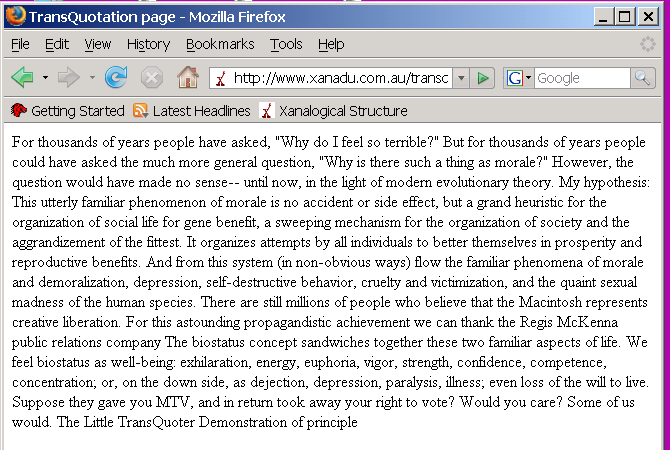
Fig. C: A page brought in by the
EDL of Fig. B
5. Connection by Transclusion
In this system, portions of
content are brought in from various sources (local and remote). The
content portions thus brought in may remain visibly connected to their
origins.
This is an important case of
transclusion, which we define as the same content knowably in more than
one place (For instance, being able to see a quotation or excerpt and
its original context in another document.)
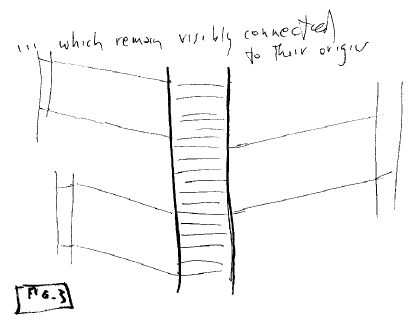
Fig. 3: Visible
connection to the origins of content
Tranclusion generalizes the
quotation. It also generalizes the anthology and the
collage.
A transclusion is like a tunnel between
the same material in different places, maintaining a live connection between
the different contexts. (Note that Bush's Memex trails were
transclusions, not links (6).)
Recognizing transclusion
internally. Behind the scenes, we compare the addresses to find
identities of content. Transclusion is recognized by commonality of
addresses.
Showing transclusion.
There are different ways to show transclusion: we do it differently in the
Xanadu Transquoter and in Xanadu Space.
The Xanadu Transquoter concatenates
quotations in a browser window and keeps them clickable. Clicking goes
to the original context.
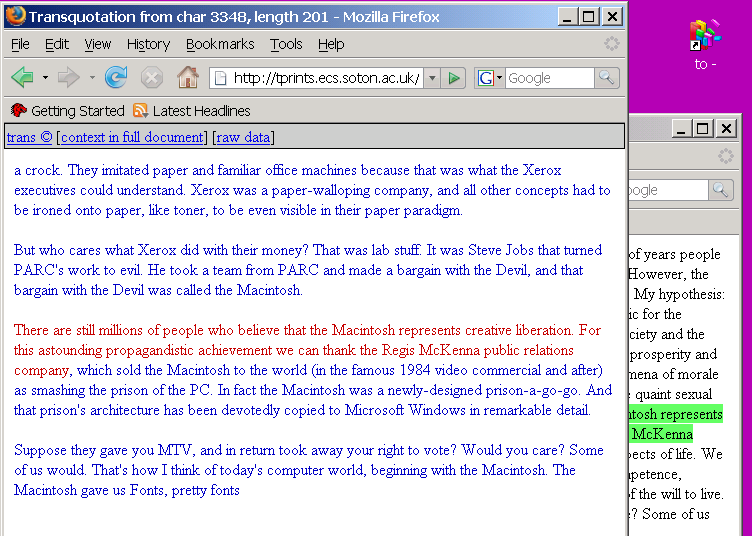
Fig. D: Transclusion shown by the
Xanadu Transquoter:
striping a quoted portion in the window of Fig. C
(shown here on the right) brings up the
original context
of the
quote in another window (left)
This can be facilitated by placing source
documents in the Eprints server, which has been given a context display
routine for the purpose (seen in foreground window, Fig. D).
Xanadu Space, a 3D document viewer, shows
transcluded content side by side between two documents.

Fig. E: Transclusion shown in
Xanadu Space:
direct
side-by-side connection
As the user goes from portion to
portion, Xanadu Space animates the document movement.
6. OVERLAYS AND FLOATING
LINKS
Relations, structure,
interaction and hypertext connections are all carried out by a single
mechanism: connection by flinks, or floating links.
Flinks may be thought of as imposed
relations for connection, structure, interaction, formatting, annotation,
metadata, and other relations of any kind. They attach directly to
content, through the permaddresses of that content.
The flink generalizes sticky notes,
footnotes, comments and any other forms of connection or
relation.
A flink is a first-class addressable
object, and may be 1-way and n-way, not just two-way.
Flinks may overlap in any quantity.
They may be built into large frameworks of relationships.
How to think of it:
- a one-sided flink
(representing, for example, a marker or sticky note), may best be thought of
as like a postage stamp glued onto the content.
- a two-sided flink (representing a relation) connects two portions
of content; we may think of it as a connection between
two patches glued onto the content.
A flink is attached to elements of
content; these elements are called its endset. A one-sided flink
has one endset, a two-sided flink has two endsets, etc. An endset need
ot be consecutive; indeed, when a document is edited, different portions of an
endset may be arranged to different places without causing a
problem.
FLINKS ARE APPLICATIVE
Finks are not embedded; they are
applicative, stuck on the content without changing it.
Flinks may overlap in any
quantity.
Flinks may be native to a document or imported from
elsewhere. A native flink is in a document's EDL.
Non-native flinks are listed in the EDL, to be used from wherever they are in
other documents.
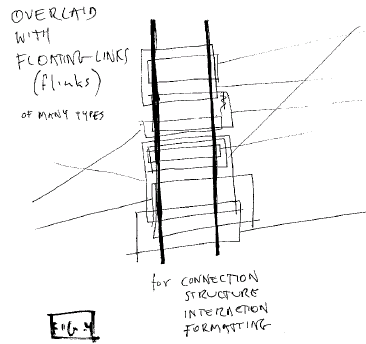
Fig. 4: Overlaying of content by
flinks
The flink is attached (by
endset) to specific addresses in content anywhere. Wherever any part of
its endset happens to be transcluded, a given flink in principle
applies.
CURRENT FLINK FORMAT
The precise format for flinks is
presently under revision. (See transliterature.org for a recent
version.)
The general form
is:
FLINKTYPE, ENDSET, (ENDSET,
ENDSET ...)
COMBINING LOGIC OF
FLINKS
Flinks may be of many
types.
- they need not be stored in
the current document, but may be brought in from other documents (like
content)
- they may not
even refer to the current contents
- they may contradict one another
(supercompleteness)
Rules for handling these different situations are part of the document
logic.
Flinks present in a document may be
turned on and off.
SCRIPTING
Because the fundamental
components are the same for all Transliterary applications, it should be
relatively simple to create any of these applications in a simple scripting
language. That will not be discussed here for space
reasons.
USES
OF TRANSLITERARY STRUCTURE
Because we are used to thinking
in terms of conventional document packages, Transliterature takes some getting
used to--
- connection to
origins
- parallel
constructions as an option
- arbitrary overlays
In what follows we will lay out some possible
uses, with emphasis on parallelism.
SINGLE-TRACK DOCUMENTS
Transliterature of course
allows plain text documents with no connections, and they need be no
different in function from plain text documents today; they are simply
maintained and delivered as EDLs. The same applies to audio and
video.
MULTITRACK
FUNCTIONS IN SINGLE-TRACK DOCUMENTS
The multitrack capability of
transliterary structure is not just for multitrack objects. It can
help with many authoring issues--
- parallel outlining, where
the outline is to the side
- where contents are on hold, either as potential inclusions or as
late cuts ("darlings"). The author can have access to this optional
content without its intruding on a current
draft.
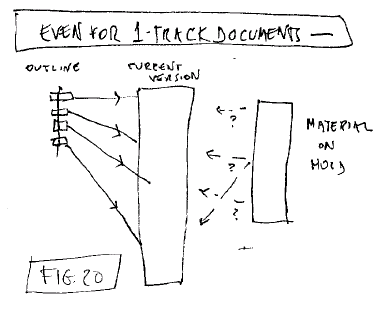
Fig. 20: Parallelism
is useful even for 1-track documents
Another authorial issue is the problem of
finding the right sequence for a piece of writing. Often it is easier to
choose sequences for particular threads in a subject or narrative, and then
merge those sequences. Transliterary structure will make this easier
with new authoring tools.
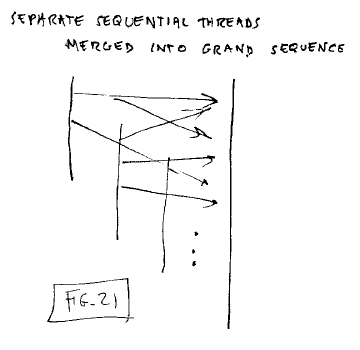
Fig. 21: Separate
sequences merged into one
Yet another authorial issue is keeping
track which content has been re-used from another version. Visible
transclusion in transliterature should make this simple.
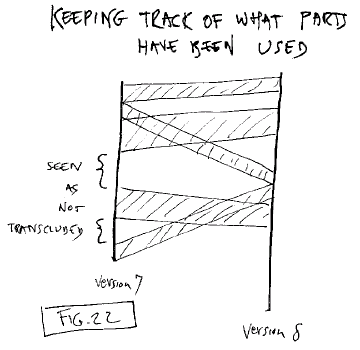
Fig. 22: Parallel strands keep
track of what contents have been used
The above textual uses should work in
Xanadu Space from its first release.
In what follows we will lay out some
possible richer, multimodal uses, with emphasis on parallelism. The uses
described are not presently working, but simple in
principle.
INTERNALLY PARALLEL DOCUMENTS:
MULTIMODAL FUNCTIONS (combining Audio, Video, Text)
Transliterary structure has many
possible uses, especially when its components are understood. For
instance, these allow the combining of text, audio and video in ways that were
not before possible. Text can annotate the audio and video, or vice
versa.
To design such uses, we create specific
tracks, assign them specific functions, and overlay them with flinks
representing the intended structures.
For instance, the annotation of audio
with text.
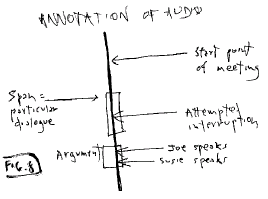
Fig. 8: Annotation of
audio
This is often called "logging,", and it
is a vital step in cataloguing audio and video.
Sync for Audio and Video Combinations
When you have more than one track of audio or video,
synchronization is generally required among the different parts. A
translit sync track can be devoted to this, and connected to the media tracks
by sync flinks.
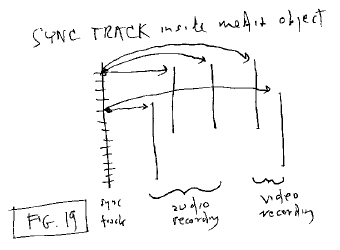
Fig. 19: Document track used for
internal sync
Note that such a sync track is oftencalled a "click
track." Click tracks were most famously used in the Looney Tunes
cartoons, where all action and music were planned to take a particular number
of time units, or "clicks."
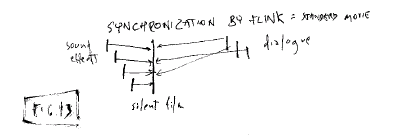
Fig. 13: Synchronization by
flink: audio for standard movie
The problem is the same for multitrack audio in a movie (fig. 13);
sync track not shown.
We can extend this to movies involving multiple
projectors. The most spectacular of these was "Cinerama," with three
projectors, in the 1950s, but we are now seeing the same arrangement with
computer projectors side by side. Translit structure can make sure the
parts start at the same time.
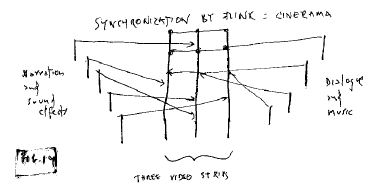
Fig. 14: "Cinerama" multitrack
synchronization by flinks
Sync track not shown.
Audio and Video
Editing In Place
It is conventional to physically rearrange portions
of audio and video to make a sequence. This makes less and less sense,
when we can simply edit virtually-- that is, create pointers to the desired
portions and put the portions in sequence.
The result is playable virtual
tracks.
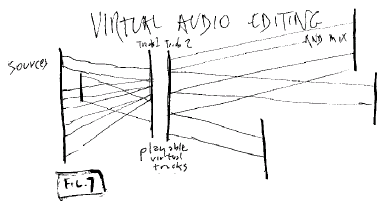
Fig. 7: Virtual Audio
Editing
This has numerous benefits--
- availability of uncut material to all
parties
- possible use of the content in numerous
new context
- transclusive access to the original
context
- transclusive access among new
contexts
This is essentially the same for
audio and video.
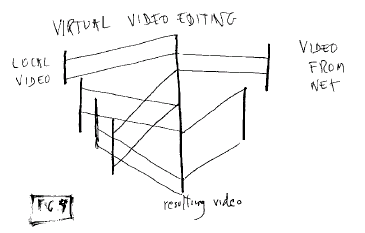
Fig. 9: Virtual video editing,
combining local and remote
sources
Overlays on Movies
Computer graphics makes it
possible to overlay movies with other shapes and text, but it makes more sense
to do this virtually than to modify the movie content itself.
Here again, translit format provides easy
mechanisms in principle. Visual annotations, graphics and animations may
be created for a wide variety of purposes.
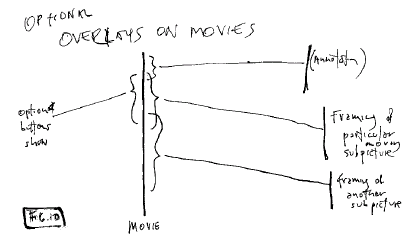
Fig. 10: Optional overlays on
movies by flink
Note that such overlays may be done even
for movies that the user does not own, such as rental films, and transmitted
separately to someone else who may want to rent the
film..
Branching
Movies
There have been many experiments
in branching movies and video-- notably the film "To Be Alive" at the 1968
World's Fair in Montreal. However, all of these were limited by
technical problems of the available media at that
time.
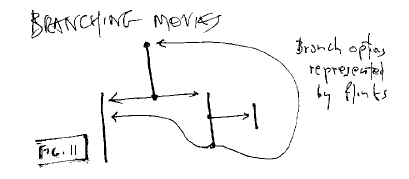
Fig. 11: Branching movies by track and
flink
However, such limitations are essentially
behind us. If video can be accessed randomly, it can be overlaid by
translit structures with any branching or interactive structure
desired.
Connecting Documents: The New
Hypertext
Today, people think "hypertext"
means the one-way links of the World Wide Web. However, this system
makes possible two-way and n-way links that will create entirely new forms of
writing and social interaction around the writing. This permit far
deeper forms of hypertext, which I have discussed elsewhere (2, 3,
4).
We see this as opening up hypertext to an
entirely different form of discourse and literary community.
Generalizing Tracks,
Interaction and Transclusion
Generalizing All Of It
Generalizing Media
With all of these components
available, we can now posit a generalized virtal medium that combines all
these aspects. It will be possible to combine audio, video, text and
branching with transclusive context availability.
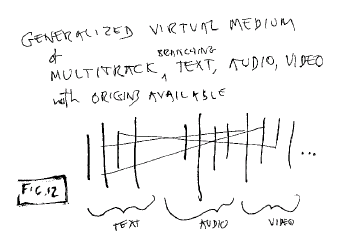
Fig. 12: A generalized multitrack
virtual medium
We consider this to be a
fundamental medium. This is the capability we have been striving toward
for so long.
Issues ----------------
UNBREAKING LINKS THROUGH UNBREAKING
ADDRESSES
There are many ways links can
change or break. Many are technical, many are political. We believe we have
solved the principal causes which are not political (i.e., based on the
actions of others).
Changes outside the transliterary system
can break links; changes within transliterary documents will
not.
Transliterary links are to spans of
content, which retain their addresses. Whereas
Weblinks (not our kind of link) point
either to
- a whole document, located at
a URL
- an "anchor"
within the document
Various things can change in non-transliterary documents (the "real
world")--
- the document may be
rewritten
- the document
may disappear, being purged or lost
- the address may cease to exist (the directory,
document or domain)
-
the address may change
-
the anchor may disappear
- the anchor may be modified
Nothing can be done about these
problems.
However, in the transliterary world, we
have solutions to several of these issues:
In-Links.
Links into transliterary documents (in-links) do not change because
addresses do not change within a document, even though the document
changes.
To publish a different version, the
transliterary publisher creates the new version as an EDL. Properly
constructed, this assures that any surviving content from the previous
version has the adddresses it had before; and that any flinks using that
content will still be in place.
Out-links. Assume
that external addresses do not change, but our documents do. If data
elements move in a transliterary document, the endsets of flinks may move or
become shorter. However, any surviving endset elements will still be
connected to the same spans of content in the remote documents. Since
our links are on spans of content, they will continue to adhere to any
remaining portions of external content, however shortened or rearranged in
our out-pointing flinks. Any part of a flink's endset still attaches
to the flink.
Our Game (Commitments of the Translit
Publisher)
Transliterary structure needs
to be maintained by certain procedures. "Players" are those who adhere
to these precepts. "Non-players" are those who do not.
To make the system work, the
transliterary publisher is committed to
- not change content
addresses.
- keep
content continuously available (no "out of print" or "no longer in
release"). The transliterary publisher makes a commitment to keep
that content available with that same address, either a URL or a UID
(Universal IDentifier).
- not bring content into a document in a way that loses the
connection to its origin.
- revise by EDL
The Non-Player's Game
We will of course have to deal
with publishers not playing our game of availability and stable addressing,
and we will still have to connect to their documents.
In particular, this
means--
Caching.
For protection, we must keep copies of any document we connect to, so that
the connection can be followed as was intended.
Tables of
identity. For content that is duplicated or moved, tables of
identity will be needed to redirect transliterary
connections.
COPYRIGHT: The New Possibility
Transliterary format makes
possible a new kind of copyright system. (What follows is a brief
summary of our general position, which will be found at
transcopyright.org.)
What we strive to achieve is expressed in
this motto:
"Everything recombinable and
republishable without
negotation."
What we are doing is made more
difficult today by the fact that everyone has a locked and frozen opinion on
copyright. Almost everyone holds one of the following
positions:
- copyright must be
eliminated!
- if we
steal all the content, the evil publishers will be put out of business, and
the world will be a place of sweetness and light
- Creative Commons will somehow fix
things
- maybe
publishers will stop charging for content, especially to idealistic people
and the poor
- copyright
control (DRM) must be stronger and more
Draconian
Our
position is different from all of these.
Transclusion makes possible a new kind of
copyright solution, which we call "transcopyright." This requires no new
laws and no change in human nature.
We want publishers who sell content for
money to make that content available for transclusive re-use (i.e., inclusion
in new documents with connection to its home context..
The
Transcopyright Approach
In transliterature, a document
is sent out as an EDL (hollow format). It is a plan for what contents to
bring in and how to arrange them.
In principle, you can put into the EDL
any part of any on-line document. The only problem is, a downloader may
not get it-- because many documents are not available for free or in
part.
By putting a work under transcopyright, a
rightsholder would agree--
- to sell arbitrary portions
of document on line, charging proportionally for the size of each
piece
- to grant
permission to anyone to include any portion of a work in an EDL, even though
that portion is now out of context
- not to change the price unreasonably, or
without due warning
Benefits to the public--
- Everything is
recombinable and republishable without negotiation (the motto above)--
provided that rightsholders participate.
- Content that is locked away and unusable
becomes usable.
Benefits to the publisher--
- a new revenue stream of very
small payments
- samples
of the work may be widely seen, with payment
- any downloader may purchase more of the
document as a local copy
- in principle the quotation is not "out of context," since the
reader may send directly for more of the
context
Misunderstandings--
- this confuses publishers,
because
- they are accustomed to
payment in advance for any re-used content
- they are accustomed to payment in advance
for a known number of copies (such as, "a press run of
10,000")
"Once
it's out there, it will be stolen."
- there is already illicit
availability of thousands of media objects; this will not change
that
- every form of
commerce has black markets and grey markets where the law is
broken
I've
heard the complaint, "This doesn't make it free!"
Why were you expecting it to
be free? Publishers have a legal and legitimate form of commerce
based on selling content; they will not relinquish this, nor should
they. This is not an attempt to subvert commercial publishing, but
to open it in a new direction.
Cost--
- as with the mobile phone,
this would become a form of commerce where people do not reckon the cost
because individual purchases are not great
- the publisher would get to set the price of
the content
- the user
could choose not to download expensive portions
- publishers would find it disadvantageous to
charge too much
The Real Hope: Objectives of
Transcopyright
What this system can do is
change the basis of re-use, eliminating red tape and making it simple
to re-use content in on-line documents. The real objective is to loosen
and liquefy the content for everyone's flexible re-use, based on showing
publishers they can benefit from this recombinable approach. Without
buy-in by large commercial publishers, it will remain simply a demonstrable
possibility.
The Transcopyright Permission System
The publisher puts the term
"transcopyright", or "trans(c)", on the document, linking it to a longer
permission statement. This tells everyone it is okay to quote in any
amount by EDL.
However, to make it operational, the
publisher will have to put the content on a transcopyright
server.
The Transcopyright Server, and
Payment Gateway
A transcopyright server will
serve up the requested portion, given the appropriate micropayment by the
user. Such a payment gateway is also not presently available. (We
also foresee services to act as payment gateway and transcopyright server,
freeing the publisher from that requirement.)
END
This approach to media and
documents is very different and requires adaptation and new attitudes.
Will it be worth it? Believers think yes, others intend to stay satisfied with
today's tangled formats and the one-way non-overlapping links of current
simple hypertext. I think much better is possible and hope it will be worth
the wait.
BIBLIOGRAPHY
1. Theodor H. Nelson,
"Lost in hyperspace." New Scientist magazine, issue 2561, 22 July 2006,
page 26. Available on line at
http://www.newscientist.com/article/mg19125610.300-lost-in-hyperspace.html
2. Theodor H. Nelson, The Future
of Information. ASCII (Tokyo), 1997.
3. Theodor H. Nelson, Literary
Machines, various editions. Published by the author; available from
Eastgate Systems ...
4. Theodor H. Nelson, "Xanalogical
Structure, Needed Now More than Ever: Parallel Documents, Deep Links to
Content, Deep Versioning and Deep Re-Use." Available at various
addresses; canonically from Project Xanadu, at
http://xanadu.com/XUarchive/ACMpiece/XuDation-D18.html
5. Theodor H. Nelson,
"Transliterature: A Humanist Format for Re-Usable Documents and Media."
At http://transliterature.org/
6. Bush, Vannevar, "As We May
Think." Atlantic Monthly, July 1945; on line at
http://www.theatlantic.com/doc/194507/bush
and elsewhere.
=30=